博亚体育app2026世界杯中国官网下载 Claude Fable 5最难档零分! 智能体的终末考研来了
发布日期:2026-06-12 17:38 点击次数:80


机器之机杼剪部
这几天,Anthropic 的最新模子 Claude Fable 5 发布之后,在 AI 圈激起了不小的漂流。
今天一早,大模子评测平台 Arena 放出了智能体基准测试(Agent Arena)的收获:Fable 5(High)排行第一,OpenAI 的 GPT-5.5(xHigh)屈居第二。另外,在「证据到手率」和「可教唆性」等两项目的上,Fable 5(High)也稳压 GPT-5.5(xHigh)。
从 Agent Arena 的跑分来看,Fable 5 的性能强悍可见一斑。该基准通过数百万个简直天下的长周期智能体任务来评估模子,需要调用网页搜索、文献系统、末端等用具,完成写代码、制作幻灯片、网页规划、构建利用以及分析文档等复杂职责流。
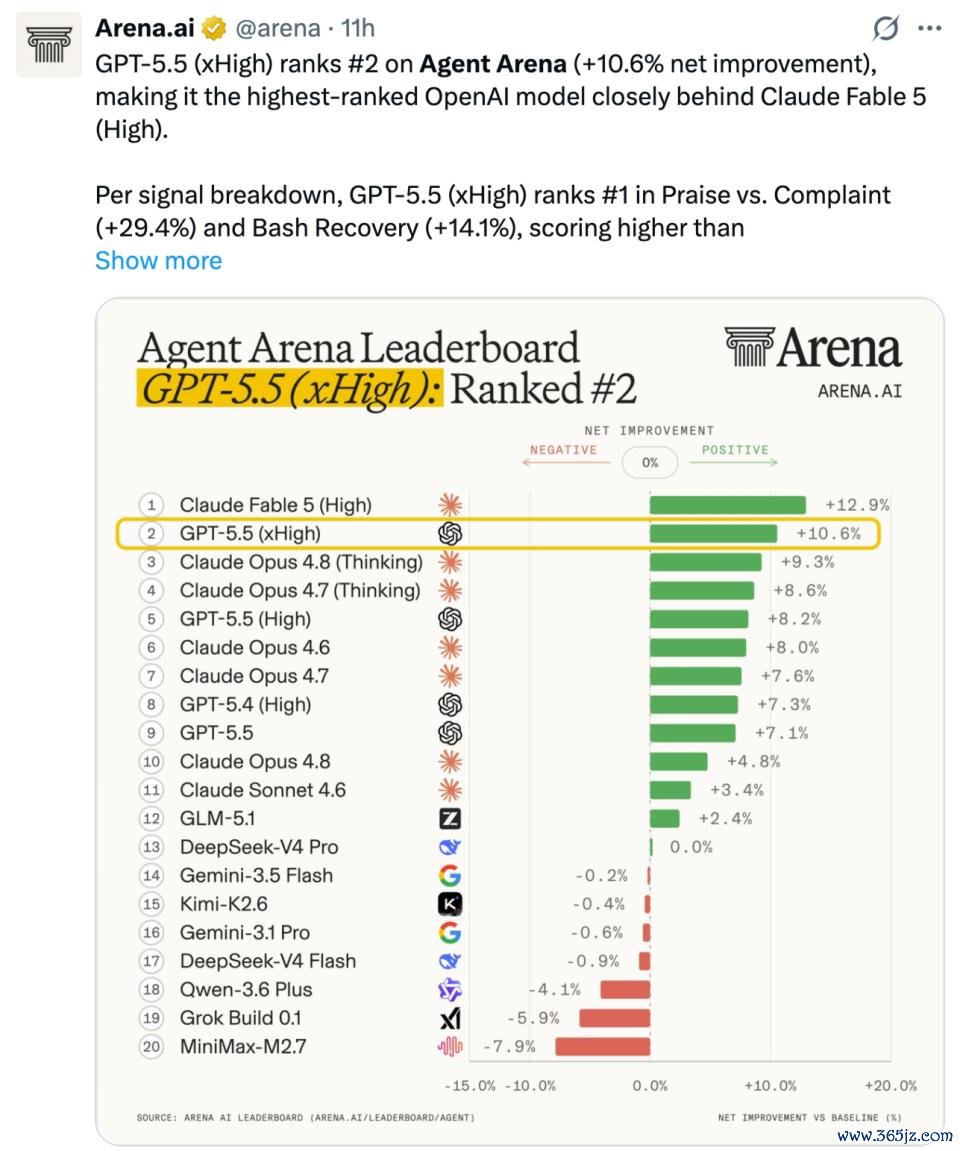
但与此同期,在另一个智能体基准测试中,Fable 5 败给了一个多月前发布的 GPT-5.5。
它是加州大学伯克利分校宋晓东(Dawn Song)教悔团队确立的 ALE,全称为 Agents' Last Exam(智能体的终末博亚体育app2026世界杯中国官网下载考研),用来算计 AI 智能体是否果然八成在平庸的简直天下限制中完成具有经济价值的职责。
ALE 测试涵盖 55 个非膂力事业,包含 1500 + 项任务,由来自 100 + 机构的 300+ 位行家孝顺,掩饰科学、工程、医学、法律、金融、莳植等多个限制。另外,该基准提供圆善的 GUI + CLI 环境,并基于最终后果进行可考证评估。
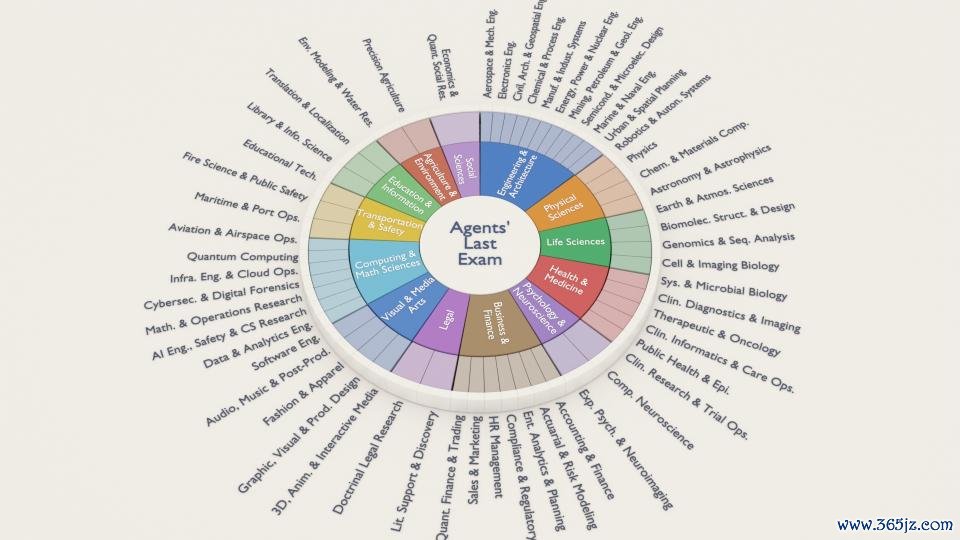
在 ALE 中,团队评测了 Fable 5、GPT-5.5、Composer 2.5 以尽头他前沿 Agent 系统。后果既令东谈主印象潜入,也糜掷让东谈主平定:
目下的 Agent 如故八成惩办格外一部分专科任务,但当咱们看向最难的那一类任务,也便是那些需要捏续推理、深厚限制学问,以及长周期可靠推论的任务时,它们距离东谈主类水平仍然很远。「有效的 Agent 时间如故到来,但简直能胜任职责的 Agent 时间,还莫得。」
团队但愿 ALE 八成成为一个新的参照系,匡助行业确立出八成在平庸限制中踏实完成经济价值职责的 Agent。
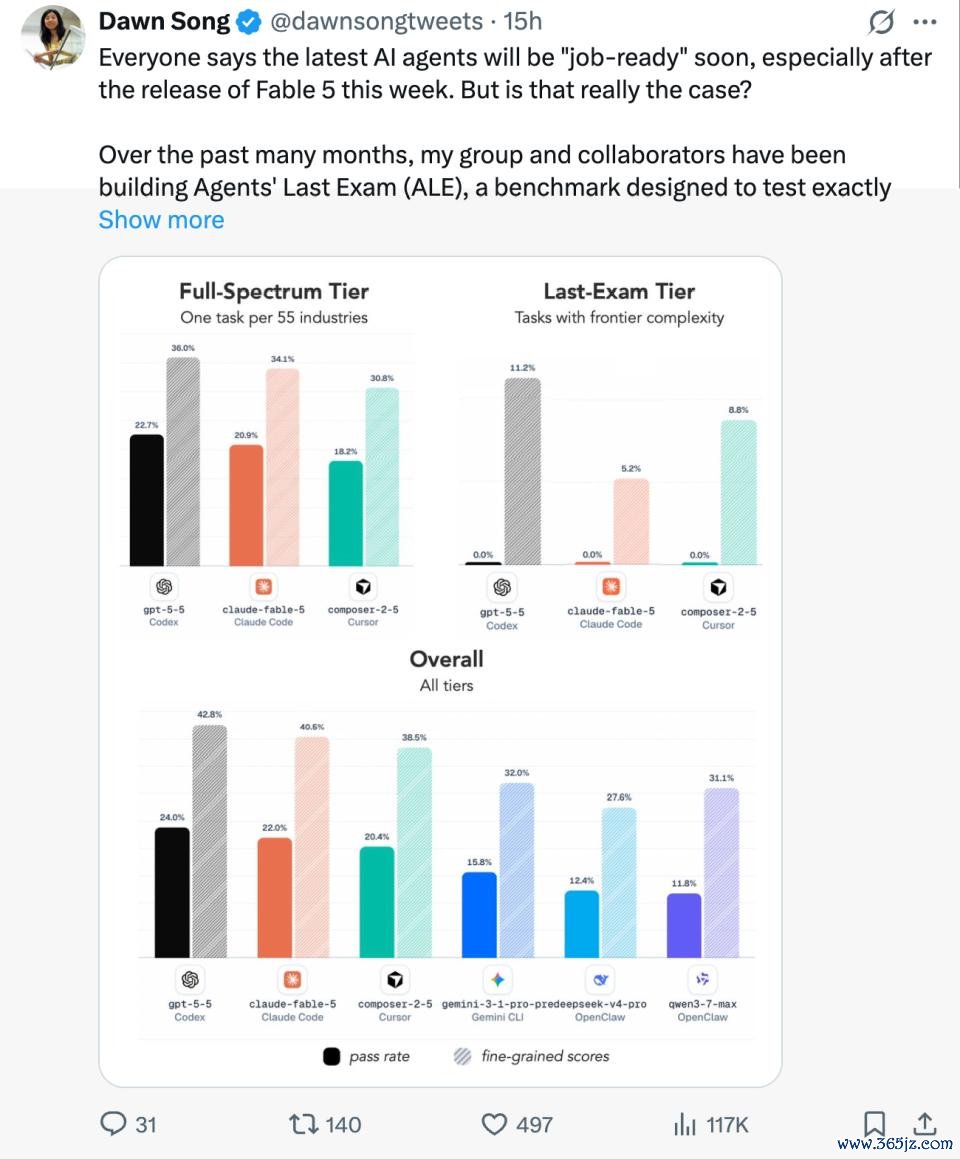
针对 Fable 5,ALE 的以下几点测试后果值得咱们包涵:
一是,在举座榜单中,GPT-5.5 凭借 24.0% 的通过率居于榜首,额外了 Fable 5 的 22.0%;余下按序为 composer-2.5、Gemini-3.1-pro-preview、Deepseek-v4-pro 和 Qwen-3.7-Max。
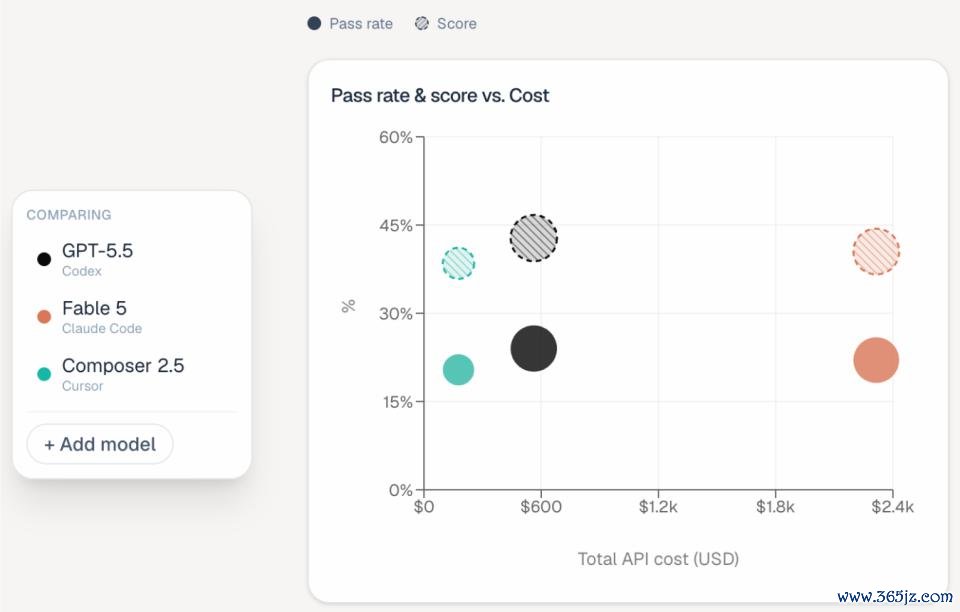
二是,资本互异纷乱。固然 Fable 5、GPT-5.5 和 Composer 2.5 的举座进展处在归并梯队,但每项任务的资本互异相配彰着:Fable 5 平均每题破耗约 $15.70,GPT-5.5 仅 $3.80,Composer 2.5 为 $1.33。
也便是说,在性能临近的情况下,Fable 5 每完成一项任务的资本爽快是其他模子的 4 到 12 倍。
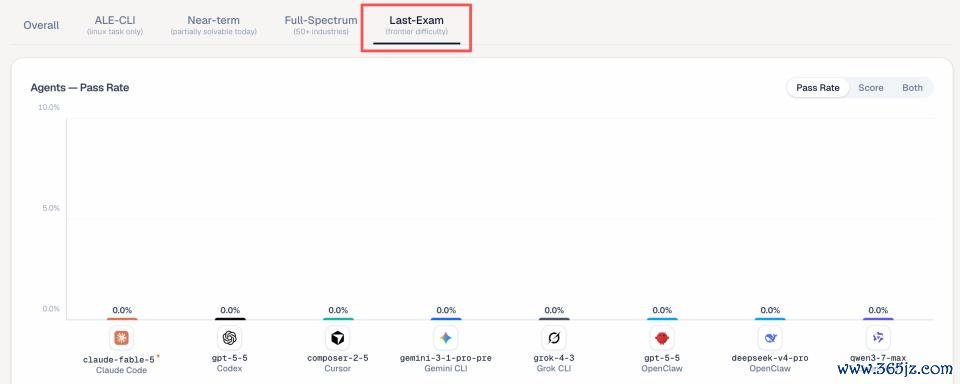
三是,最难一档拔本塞原。在最高难度「Last-Exam」档位,包括 Fable 5 在内的统统前沿 agent 通过率为 0%。
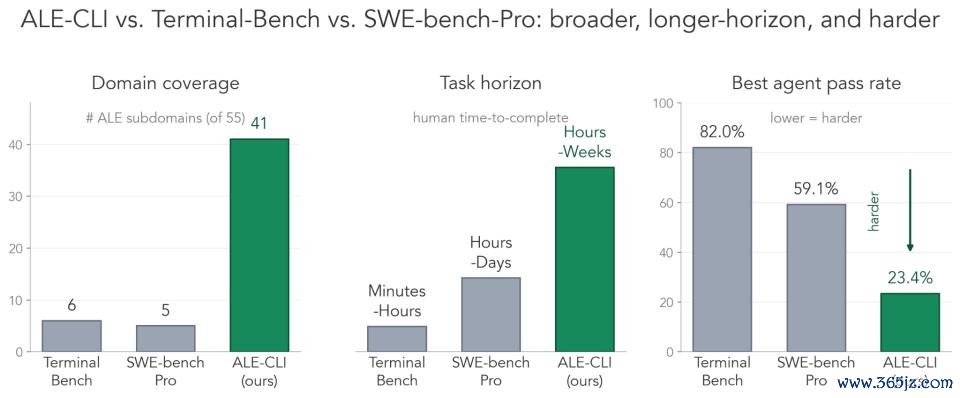
另外,ALE 中还有一个仅支撑敕令行环境的子集 ——ALE-CLI。
比较 Terminal-Bench 和 SWE-bench-Pro,它的掩饰范围更广、任务周期更长,难度也彰着更高:
掩饰更广:ALE-CLI 的任务掩饰 ALE 55 个行业子限制中的 40 个;比较之下,Terminal-Bench 只掩饰 6 个,SWE-bench-Pro 只掩饰 5 个。
周期更长:东谈主类完成这些任务常常需要数小时到数周,而不是几分钟到几天。
难度更高:进展最好的 Agent 通过率也唯有 25.2%;比较之下,Terminal-Bench 上的最好通过率为 82.0%,SWE-bench-Pro 为 59.1%。
这阐扬,Agent 离简直熟谙还有很长的路要走,也还有很大的擢升起间。
开云体育app2026世界杯中国官网下载
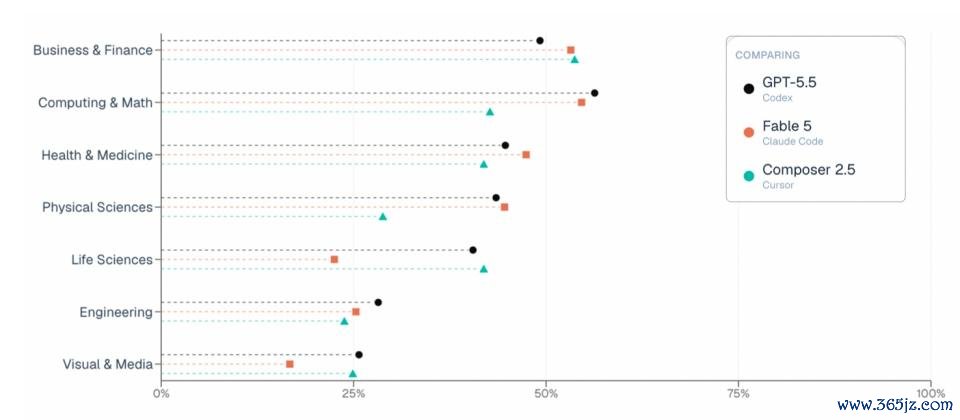
在谈到为什么 ALE 的后果和一些其他基准不太一样,尤其是 Fable 5?宋晓东暗意,原因很简便:不存在一个在统统场景下都最强的 Agent。包括 Fable 5 在内,每个前沿模子都有我方擅长的限制,也都有进展难题的限制。
总分会把 55 个事业、1500 多个任务的后果平均到一齐,因此好多模子的分数会挤在临近区间。但简直遑急的,不是平平分。简直有价值的信号在于:Agent 在那里到手,在那里失败,以及这些成败模式何如随限制而变化。相通的任务,博亚体育app2026世界杯中国官网下载不同模子失败的原因常常皆备不同。
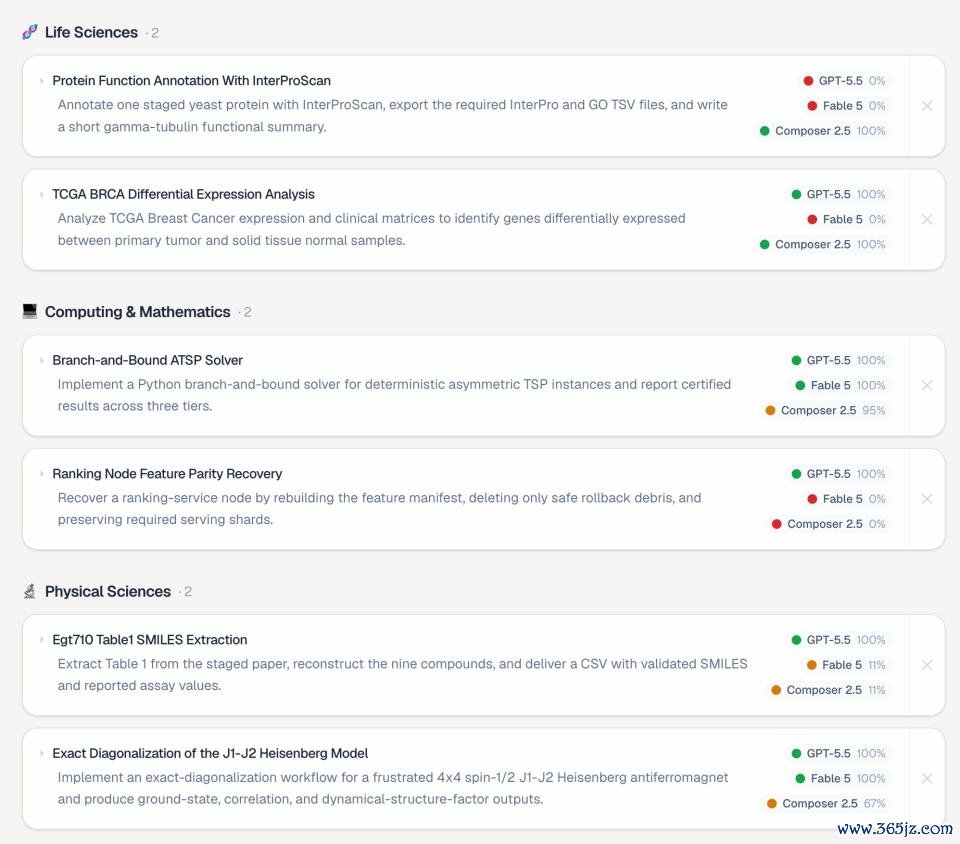
最常见的失败模式依然是一个熟悉的问题: Agent 还莫得简直考证我方的职责,就先告示任务完成。典型的完成回话常常是:「已完成,统统查验都通过了。」但内容输出可能空匮必要文献、统计数目有误、遗漏关键字段,或者违背了任务阐扬中明确写出的抑止条款。
ALE 规划先容

ALE 是一个包含 1000 多个任求实例的基准测试,掩饰 55 个子限制和 13 个行业集群,由来自 100 + 机构的 300 + 位行家孝顺。
为了确保行业掩饰糜掷平庸且具有代表性,行家参谋人委员会会梳理各个限制的职责流图景,并基于 O*NET / SOC 2018 事业分类体系,识别具有经济意旨的职责流类型。
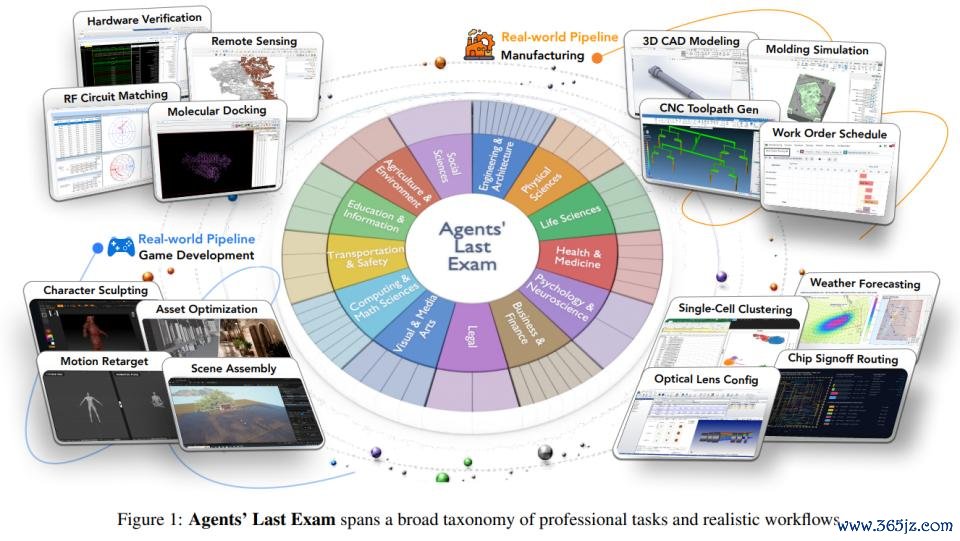
ALE 任务职责流来自简直的专科履行。它并不是凭逸想象合成场景,而是由行家提供他们如故完成过的简直神色。这些神色在被纳入基准之前,还要经过多轮质料遗弃,包括初步审核、工程师试启动,以及行家委员会的最终同业评审。
大大都任务都要求智能体使用规画机,并在 GUI 交互和 CLI 操作之间往复切换。GUI 交互包括桌面利用、浏览器和特定限制软件;CLI 操作包括 shell 剧本、代码推论和文献处理。
这意味着,ALE 要求智能体同期具备多种能力,而这些能力在现存基准中常常是被分开测试的。
ALE 的标的评测对象是 GCUA(Generalist Computer-Use Agent)智能体,举例 Claude Code 或 Codex。这类智能体八成在归并个行径轮回中不绝视觉感知、代码推论、用具使用和长周期贪图。按照想象,ALE 的任务形态掩饰范围要大于仅测试 GUI 的基准,举例 OSWorld,也大于仅测试 CLI 的基准,举例 Terminal-Bench 。
在职务集聚上,ALE 不是纰谬集聚一些任务来考验 AI,而是要求任务必须险恶三个条款:
代表性。职责流应当合适简直的专科履行,并使用限制行家内容会使用的软件。举例,建筑限制行家在把 2D 蓝图治愈为 3D 模子时,常常会使用 SolidWorks 或 Rhino,而不是 AutoCAD。
复杂性。一项任务应当是端到端的录用物,需要行家参加格外时候完成,而不仅仅几个简便的 UI 操作。关键分别在于:这是一个职责流,如故一个单一行为。
可考证性。输出后果应当八成收受确定性查验,或者八成按照与可不雅察居品绑定的明确评分笃定进行评估。最理思的情况是,录用物具有确定性,不错径直与参考输出进行比较。即使无法作念到精准匹配,判断也应当八成复原为对某个可测量居品的评估。
另外,ALE 中的任务不是由泛泛众包工东谈主来提供;而是来自限制专科东谈主士的简直日常职责,并经过严格筛选,以确保简直性、复杂性和时刻可推论性,共包含五谈关卡。
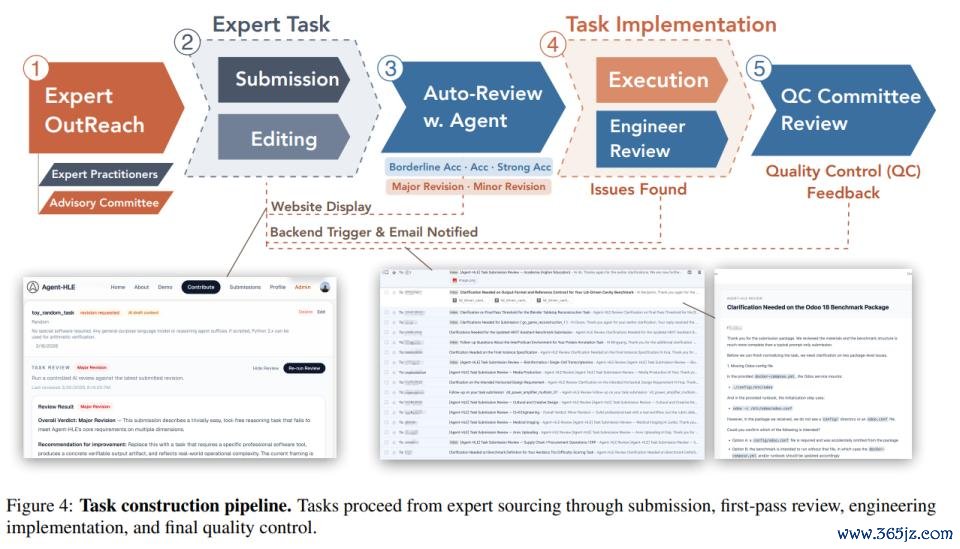
行家着手。规划者通过由行业从业者构成的参谋人委员会招募限制行家,确保任务八成掩饰统统这个词分类体系。
任务提交。行家通过专诚的网页进口提交任务提案。他们会上传我方畴昔完成过的神色,这些神色常常需要数天致使数周的专科职责。AI 援救用具会匡助完善每个提案,直到五个中枢构成部分被圆善阐扬:当然谈话边幅、输入文献、标的软件、预期录用物和评测程序。
初步审核。提交内容会按照类似学术会议审稿的步地进行筛选,给出大修 / 小修、角落继承、继承、强继承等决定;需要修改的任务会复返给行家络续完善。
任求竣事。通过审核的任务程序会被升沉为可启动的资源、配置好的软件容器,以及编码后的评测逻辑。工程师会进行试启动;一朝发现缺口,任务会被自动复返给行家补充。
最终质检。终末由行家委员会进行同业评审,核查参考输出是否正确,评测畛域是否校准合理,既不可窄到险些不可能通过,也不可宽到造作宽松,同期证据任务险阻文是否充分。
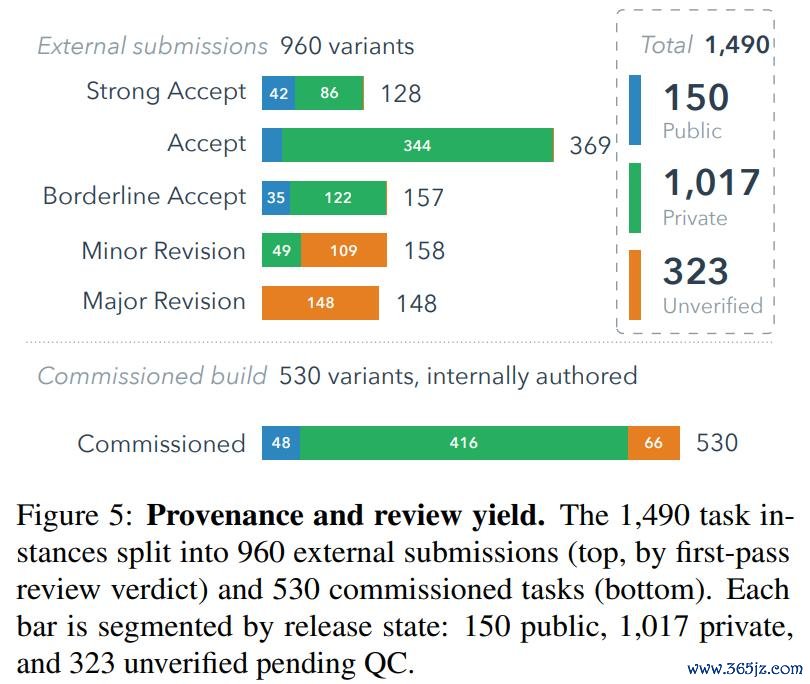
值得一提的是基准欺侮问题,这种欺侮可能来自预磨真金不怕火数据类似,也可能来自针对具体任务的优化。为此,ALE 只公开 1490 个任求实例中的 150 个,约占 10%;其余任务保留在独到池中。
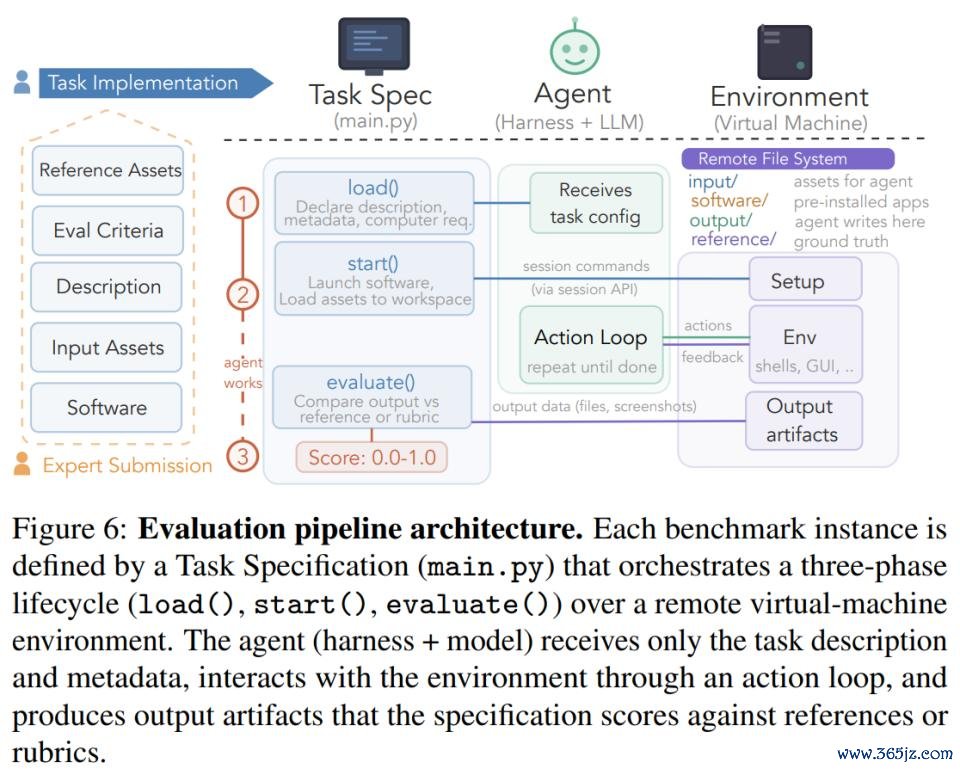
在具体评测进程上,ALE 将一个基准实例拆分为三个互相解耦的组件,这些组件通过界说了了的接口进行交互。
终末,团队但愿 Agents' Last Exam(ALE)八成成为一个新的路标和北极星,指引行业确立出八成在平庸限制中可靠完成经济价值职责的智能体。
